2. Analysis of Scale-out Ability of Akka Sharding cluster¶
跟很多分片集群解决方案不同,akka 分片集群(sharding cluster)中每一个节点都在直接访问本地数据的同时,也都可以作为 proxy 访问集群中其它节点的数据。在我看来,这是 akka 分片集群水平扩展(scale-out)能力可能接近线性的关键。
Comparing to some sharding solutions, Akka let you access whole sharding cluster data via any node.
2.1. Benchmark¶
在采用 Raspberry Pi 2 Model B 组成的 10 x nodes cluster ,我用 astore 测试了 akka 分片的水平扩展能力,结果显示出非常好的线性。我们不妨在此做个简单的分析。
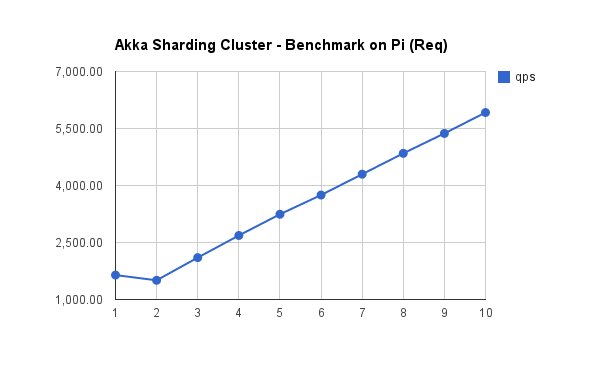
2.2. Evaluate¶
设 c 为 number of connections,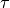 为average response time(平均响应时间),则单节点(single node)时 qps 为:
为average response time(平均响应时间),则单节点(single node)时 qps 为:
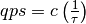
当节点数(number of nodes)为 n 时,数据(data)有  的概率
(probability)在本节点(local node),而
的概率
(probability)在本节点(local node),而 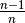 的概率(probability)在
其它节点(remote nodes)。假设在本节点(local node)的平均响应时间(average response time)
仍然为
的概率(probability)在
其它节点(remote nodes)。假设在本节点(local node)的平均响应时间(average response time)
仍然为 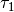 ,在其它节点的则为
,在其它节点的则为 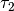 ,则总体的平均响应时间(total
average response time)为:
,则总体的平均响应时间(total
average response time)为:
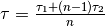
这时,qps 为:
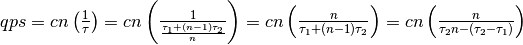
当 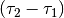 随着 n 的增加(increasing)而越来越小于(less than more and more)
随着 n 的增加(increasing)而越来越小于(less than more and more) 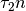 时,我们可以开始忽略(ignore) 项,也即:
时,我们可以开始忽略(ignore) 项,也即:
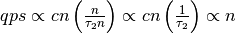
2.3. Verify¶
下面我们看看几个测试中实际的数据:
连接数 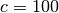
单节点(single node)时,平均响应时间 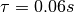 ,则:
,则:
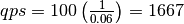
多节点(multiple nodes)情况下,假设 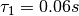 不变,根据测试数据可以估算出
不变,根据测试数据可以估算出 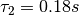 左右,则:
左右,则:
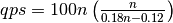
从这个公式可以看出,当 n 逐渐增大(increasing)时,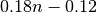 中的
中的 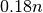 比重很快上升,当 n = 7 时,
比重很快上升,当 n = 7 时,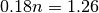 ,已经是 0.12 的 10 倍(times),
,已经是 0.12 的 10 倍(times),
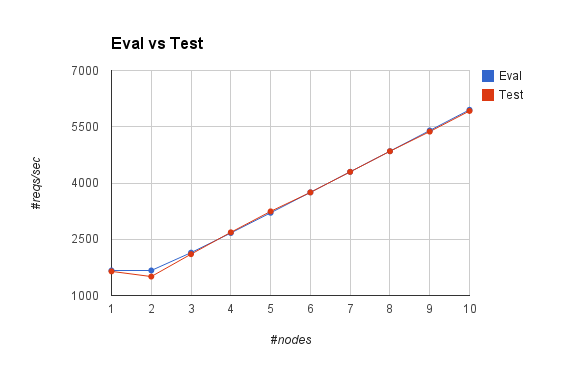
那么这个公式是否真的有效呢?我计算了 n 从 2 到 10 的数据,跟实测数据很接近:
| n | Eval | Real |
|---|---|---|
| 1 | 1667 | 1643 |
| 2 | 1667 | 1505 |
| 3 | 2143 | 2102 |
| 4 | 2667 | 2685 |
| 5 | 3205 | 3243 |
| 6 | 3750 | 3749 |
| 7 | 4298 | 4297 |
| 8 | 4848 | 4846 |
| 9 | 5400 | 5370 |
| 10 | 5952 | 5920 |